
做这个项目,最初是为了学习python,因为工作是做硬件,没有太多机会在工作中被迫用python做个项目,所以在2021年中,工作有点空闲时间,实在也想不到做什么意义的开源项目,索性就搞搞俗气的量化交易,一是数据量比较大,可以有很多机会去搞数据处理,二是闲钱比较多,可以更快的亏掉
项目的github地址:https://github.com/zhouyousong/ZfinanceUI
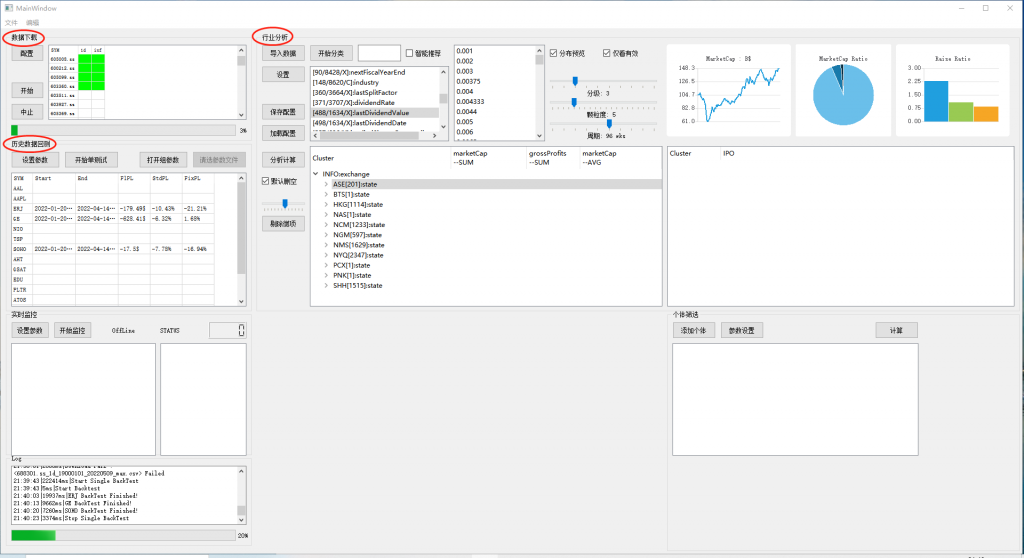
安装说明和简介请到github查阅 https://github.com/zhouyousong/ZfinanceUI 本页面主要介绍使用方法,由于开发尚未完成,所以会不断更新,界面上也会有瑕疵,目前主要完成了数据下载,行业分析,历史数据回测三大模块
第一集:下载数据和分类分析(2022年5月8号)
安装完后第一步,下载数据,一定注意代理要指向你自己的代理地址和端口,我这里是我本机的
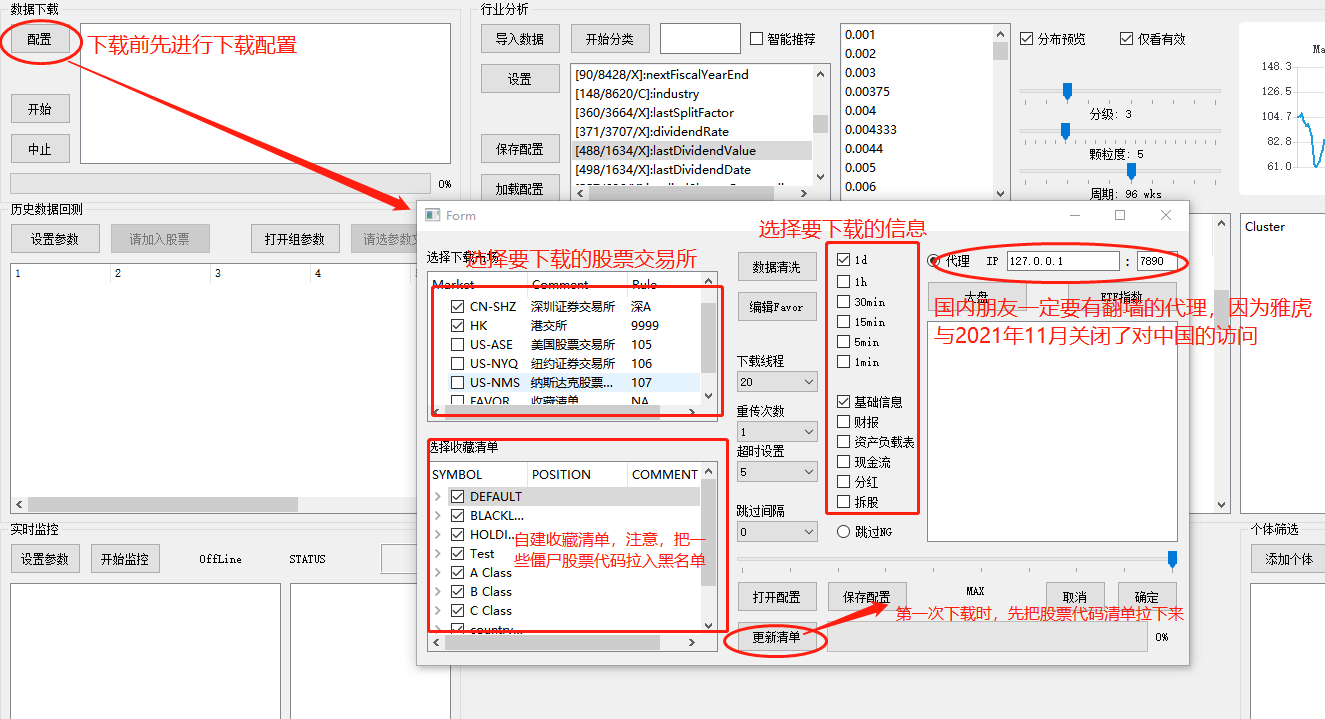
配置完成后,确定,或者保存下配置,保存为Default.ZFCfg 后缀名不要改,下次打开可直接加载之前的配置,接下来就可下载,点中止也可停止,下次开始可断点续传,但是由于当时多线程运用不熟练,所以重新下载前,会把全部数据扫描一遍,稍微有点慢,后续可能重写这部分
数据下载完成后,可以到行业分析里去玩玩儿
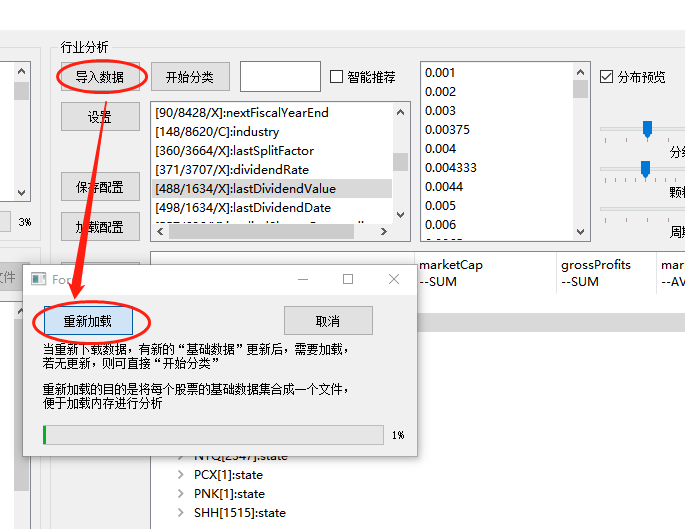
第一步,导入数据:由于每支股票都有一个独立的属性文件,几千支股票就是几千个文件,每个文件很小。导入数据时将几千个小文件合成一个大文件,方便分析加载内存,这个步骤只需要在新的一次下载完成后执行一下,不停读文件比较慢
数据导入完成后,就可以用分类,将属性中的信息提取出来,原理简单解释一下,比如10000支股票,属性里面有些是很容易分类的“注册地”,“所属行业”,“所属板块”;当然还有些属性是不能分类的,如“上市时间”,“市值”,“毛利率”,这些几乎每支股票都不一样,但是这些数据可以用于计算总和,平均值等!那么容易分类的,我会标注个C,适合于计算的,我会标注个O
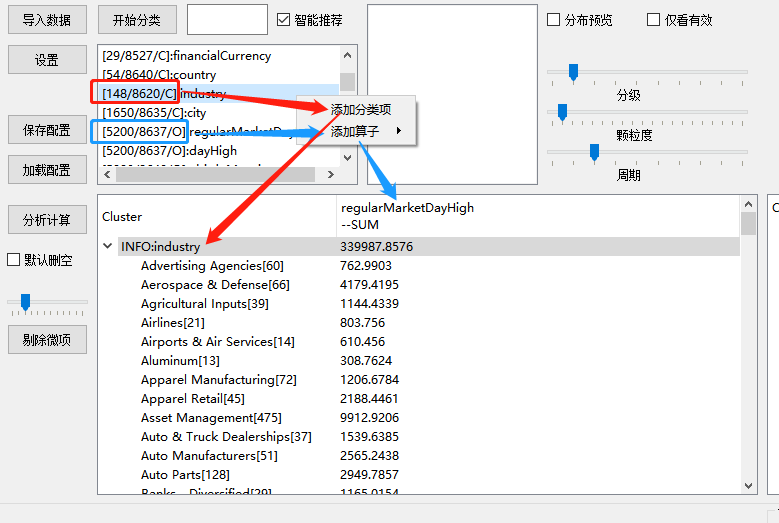
在第一列右键,分析计算,刚才添加的算子的计算结果值就出现了;把上面的分布预览勾上,那就可以看到里分类出来后的这些股票集合的总市值走势
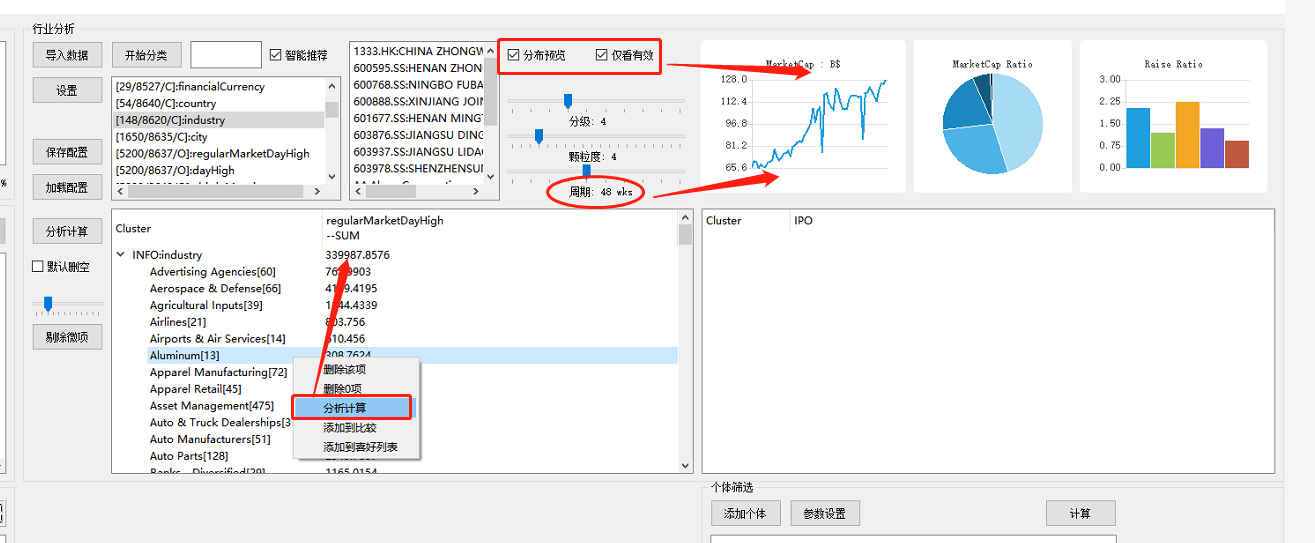
由于可以在分类下继续添加分类(注意继续添加分类前,需要选中要在哪个层次下继续分类),如上功能可以帮助各位分析师进行行业分析,比如: 香港上市的北京的通讯行业在,是个什么趋势,也可以简单的排序,如下,可以看到排除一些极小项,杭州在港股上市的公司平均市值最高(前提是我的数据源和算法没问题,欢迎大家帮我核算找出bug)
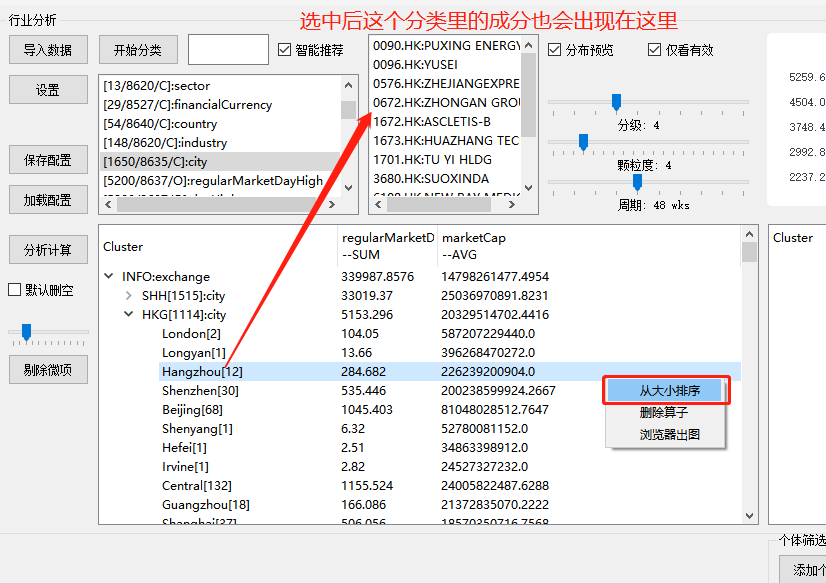
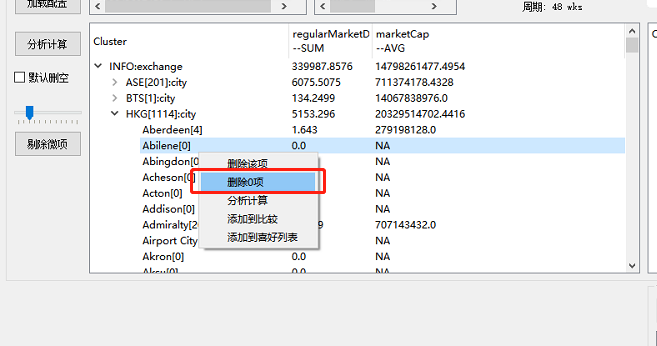
当然,有些属性拆解出来可能会是0,可以删除,方便查看
如果找到了一个很好的分类,比如北京的通讯业,那么可以把这个分类里的成分股全部添加到收藏(喜好)列表,我会自动生成个名字,比较长,建议你自己建个名字
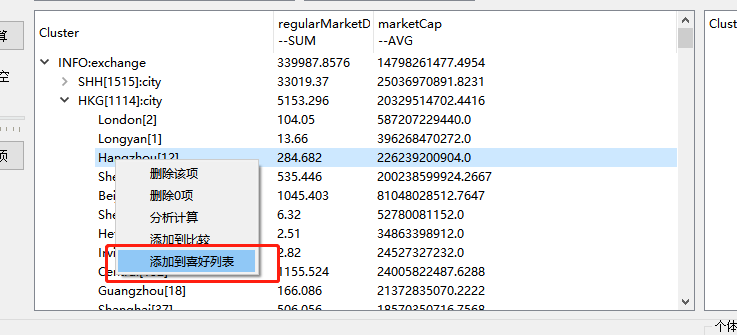
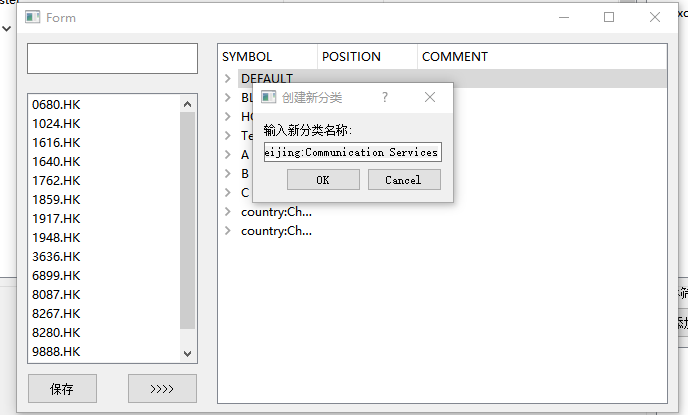
当然,也可以将两个分类添加到右边的比较框里,进行简单对比,但对比啥,我还真的没有想好

接下来是回测(未完待续)
第二集:历史数据回测(2022年5月15号)
历史数据回测模块,目前做了一个固定策略,使用5分钟数据文件进行回测,这个策略的参数可调,但是策略本身不可调,后续打算把策略接口定义一下,然后可以开放给爱好者自己写自己的策略
目前策略的逻辑大致是这样,判断之前是不是处于下降趋势,如果有一段指定长度(参数TrendDnRatioLen)时间的下降趋势后,那么当开始上扬的时候,AMEA8穿过AMEA21,50,144,200,那么就出现了买入信号;当RSI大于设定值,或者AMEA8下穿 AMEA21,50 时,出现卖出信号。当然中间还有很多参数 ( 比如靠近率,我自己发明的)可以微调,这个策略很简单,因为目前不是我工作重点,我主要工作是把工具链打通,方便组参数群体股票自动回测,其实这也是我做这个工具的主要原因:我之前在thinkorswim上用它的脚本语言(thinkscript)写策略也可以回测,但是一次智能测一个股票,用一个参数,如果想好几个股票一起测,或者好几组参数一起测,只能手动,于是我才动了心思打造这个工具。
下面就来说说回测模块的使用方法
第一步,添加要回测的股票,当然添加的列表是从收藏清单里面添加,如果不在收藏清单里,那需要里先把自己想回测的股票添加到收藏清单里,编辑喜好列表按钮在下载配置页面里(后续要提出来在菜单你们去),也可以用上面分析分类后直接全添加到喜好清单
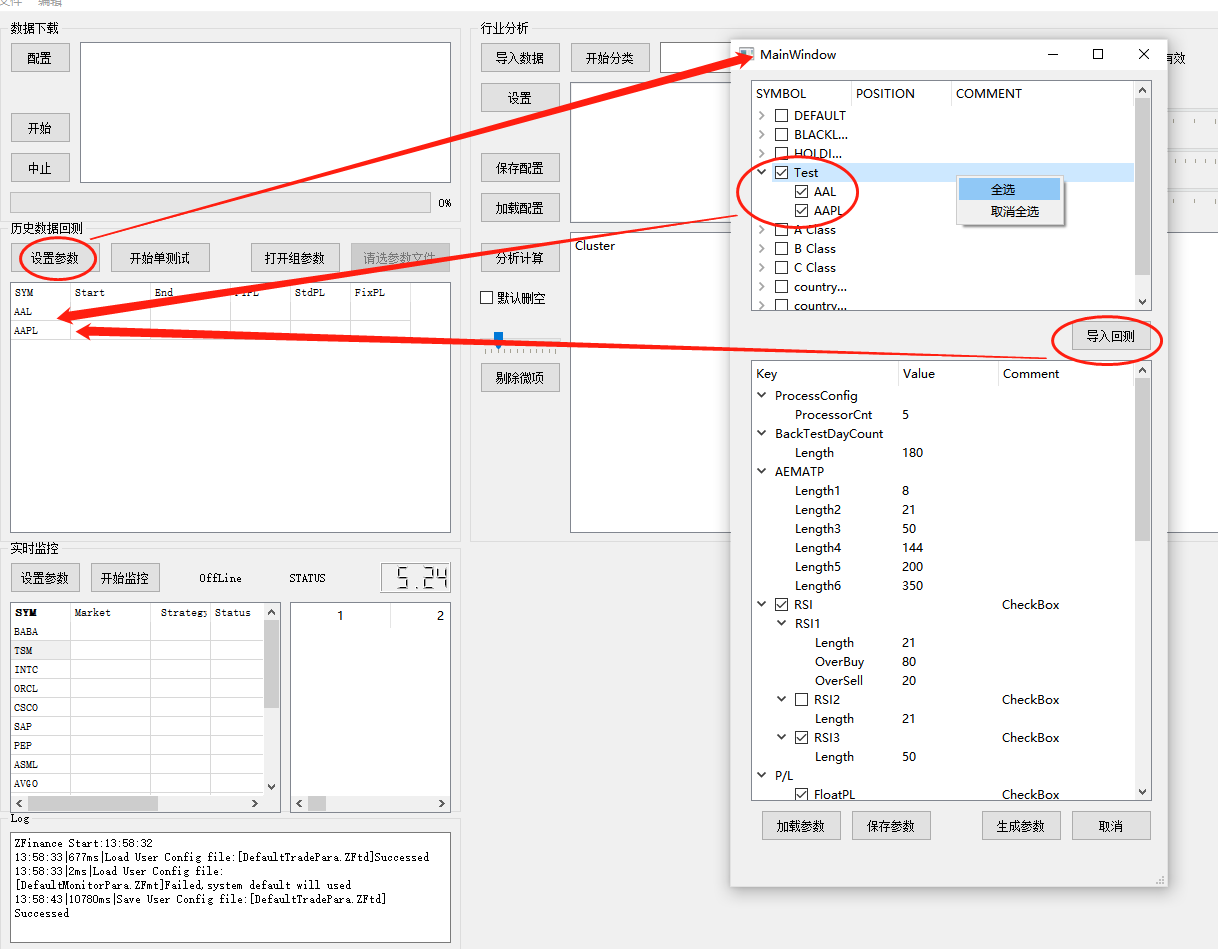
添加好回测的股票代码后,可以修改回测参数,回测参数主要的我解释一下,其他的我不一一解释了,后面可能出文档专题来讨论策略,这个话涉及与贪婪人性去博弈(2022.5.15写于上海),太难了

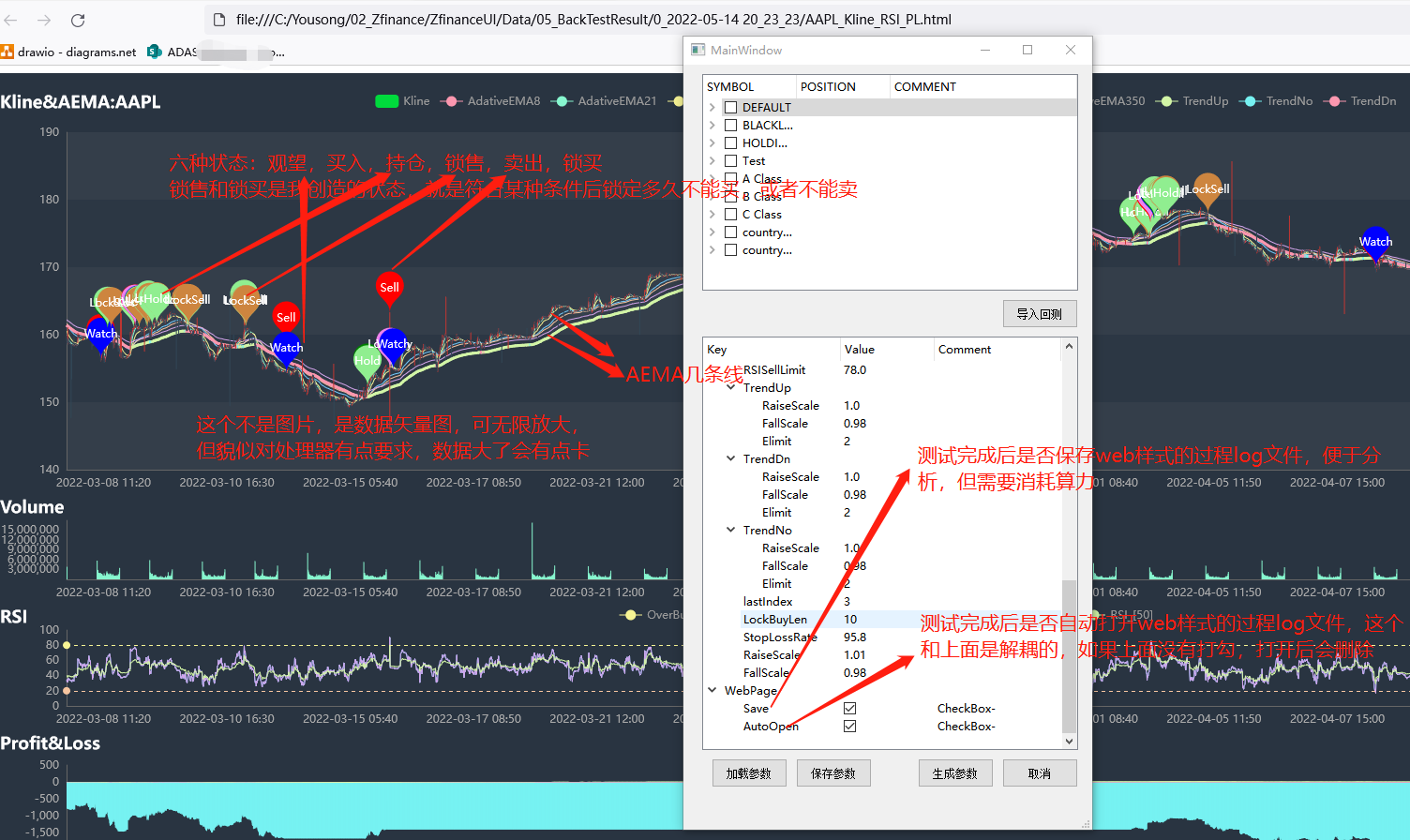
设置好参数后,点击”开始单回测”,回测随即开始。当然,回测完成后会生成csv格式的log到ZfinanceUI\Data\05_BackTestResult文件夹下
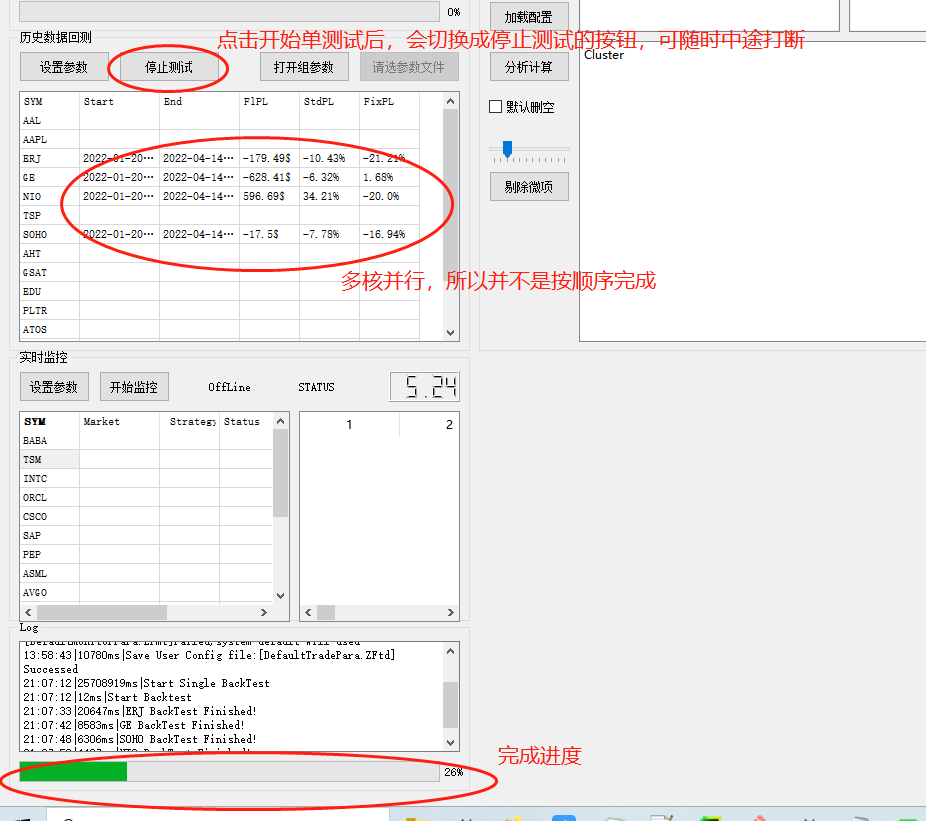
接下来说一下组参数,这个是我花了比较大的精力去设计的玩意儿。先说一下目的,比如一个策略里面可能有10个参数,那么相当于10个维度,调整第一个参数,其他参数不变(此时第二个参数假设是0.4),假定第一个参数在0.3的时候是最优(假如收益30%);基于此再调整第二个参数,其他参数不变,第二个参数可能在0.5的时候收益最大( 假如收益40% ),那是假如其他参数(3~10号)不调整,只调整第一个参数和第二个参数,是不是这个0.3配上0.5就是最大收益呢,显然不是,因为我们并没有尝试0.2配0.7。这个组参数测试,其实就是暴力尝试各种参数的排列组合,让计算机帮你遍历你指定参数组合,找到最大收益。
这样做很蠢,但是我当前还不会机器学习,这更像暴力破解密码的思路,下面就来说说,如何生成各种参数的排列组合,并进行暴力测试
如下图所示,再comment这一列,用“:”作为分割符号,按照图例,即刻生成该参数的序列值,如果有两个参数,则会生成两个参数交叉排列组合的参数,如下图,最终生成呢10*3*3=90组参数(这里应该有点>=,>的bug,细节后面处理)
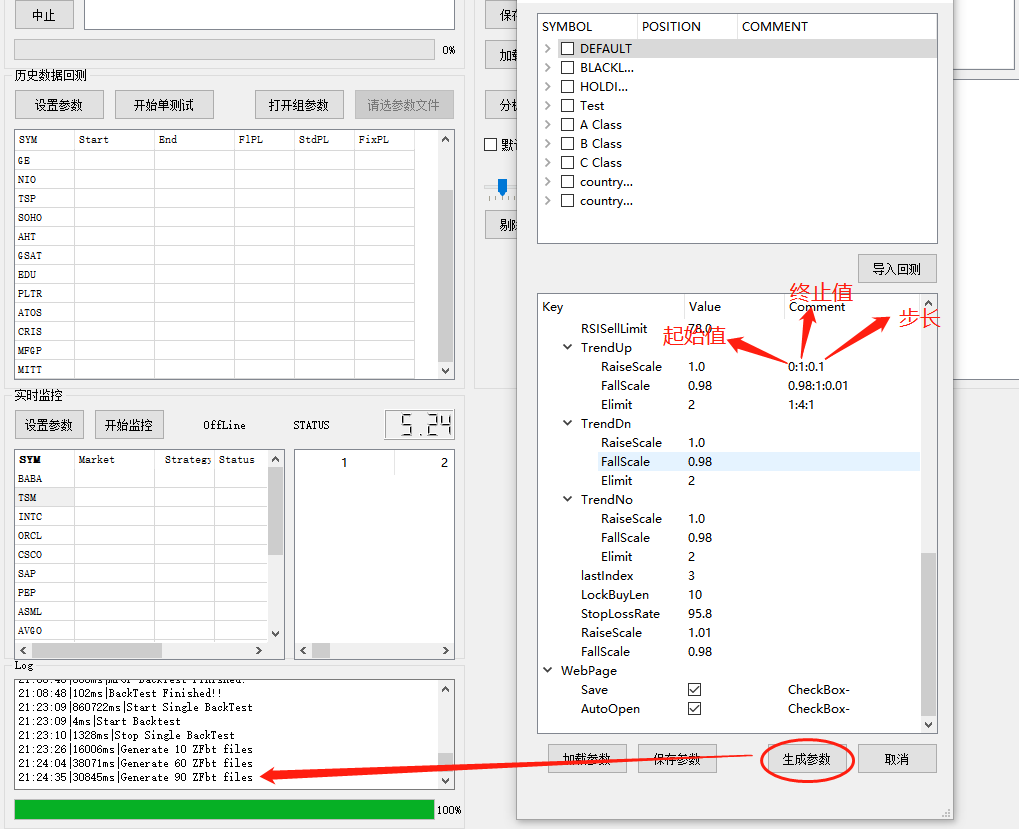
生成完成参数有,那么就可以加载这些参数组,开始组测试
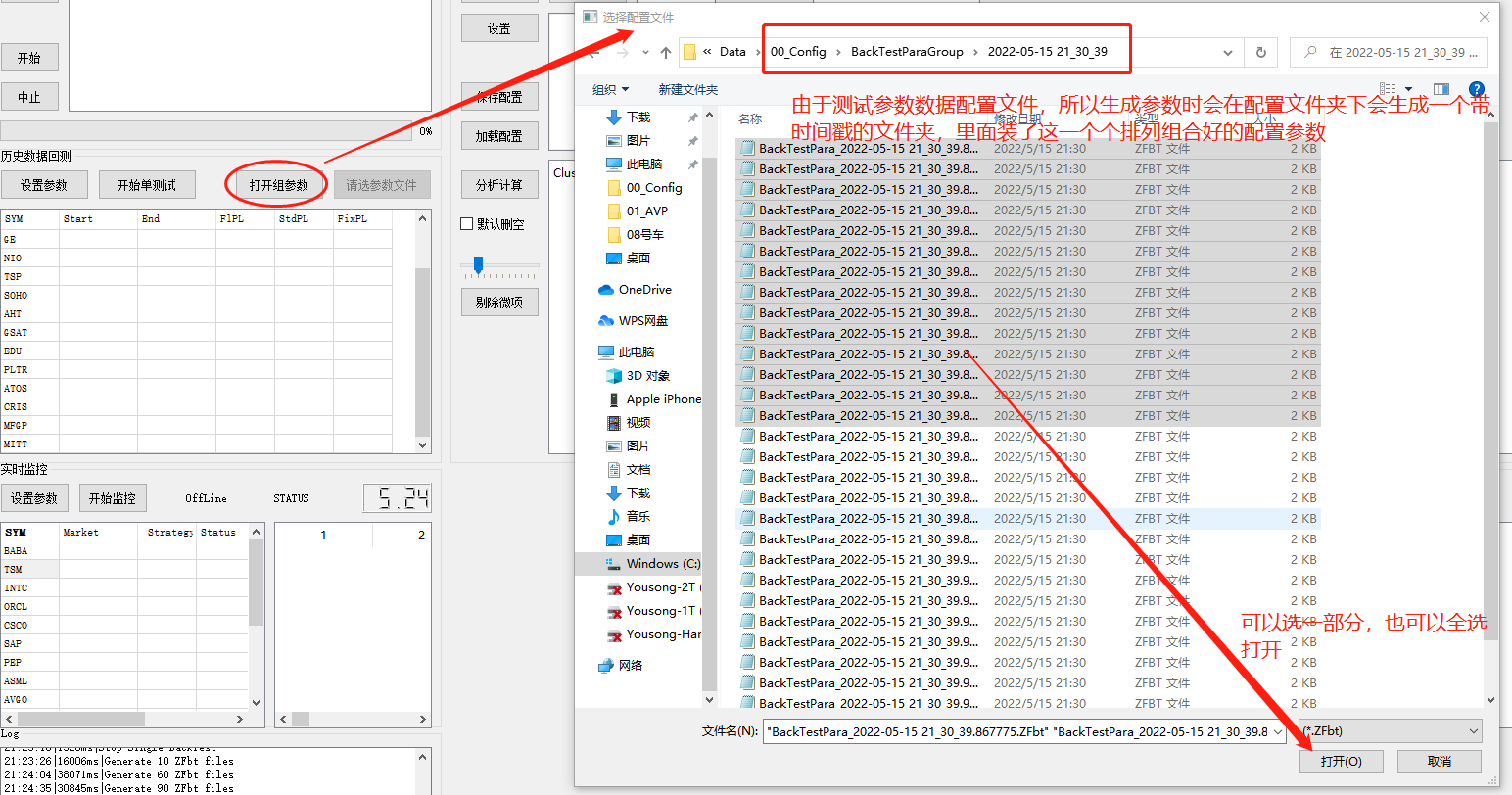
打开了组参数后,后面的开始组测试才可按下,否则时灰色不能按下的
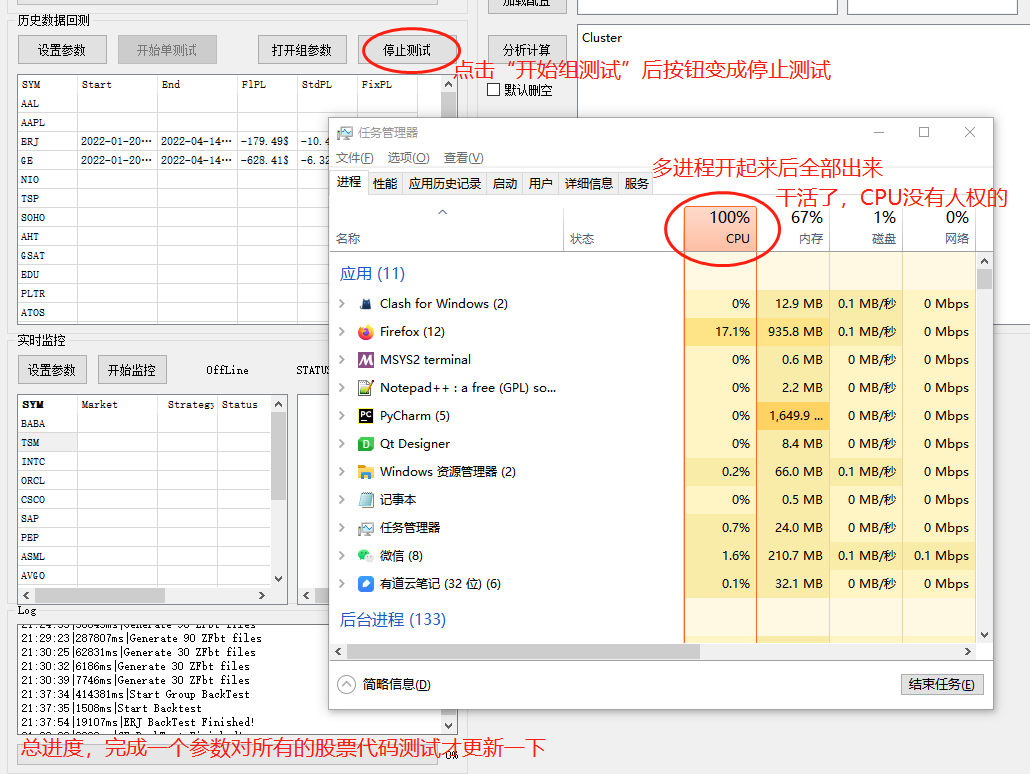
接下来是个重点,组测试的结果如何呈现:如下图,排列出来了90个参数,那么每一个参数,测试20只股票,最后会用这些股票的收益率加总,然后得出一个结果,用这个结果,加上时间戳,命名一个文件夹,然后文件夹里面时测试结果,和用的参数文件,这样,可以通过文件夹排序找出最大收益率的参数,同时,当时测试用的什么参数也在里面
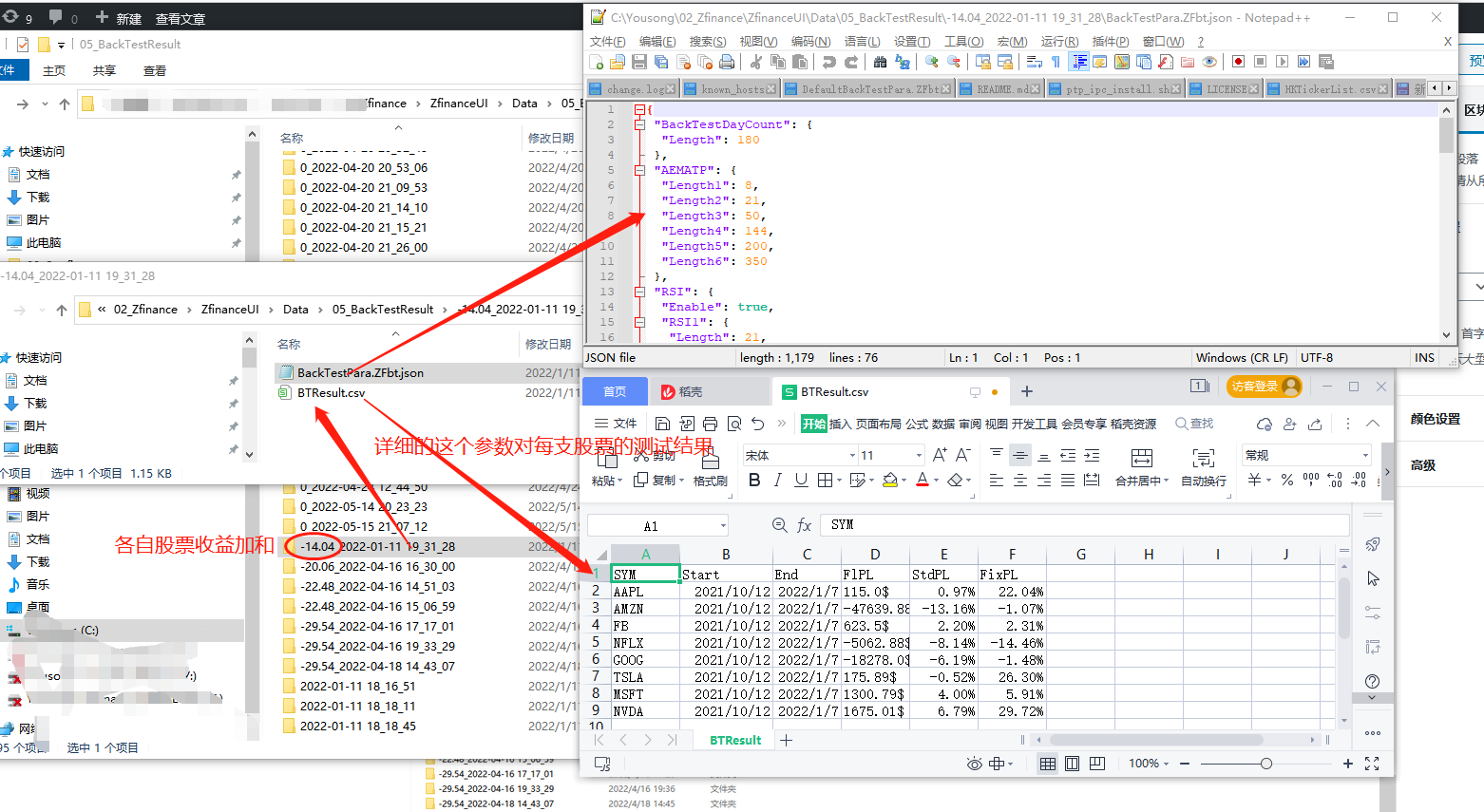
好了,以上就是回测的设计思路和使用说明,很简单粗暴,但我也不知道这个思路对不对对不对,欢迎讨论



大神啊